
TL;DR
Claude Fable 5 launched June 9, 2026 as Anthropic's first generally available Mythos-class model, sitting above the Opus tier. It shares the same underlying model as the restricted Claude Mythos 5. Fable adds safety classifiers that reroute high-risk queries (cybersecurity, biology and chemistry, distillation) to Claude Opus 4.8.
It is, in Anthropic's words, "state-of-the-art on nearly all tested benchmarks of AI capability" (80.3% SWE-bench Pro, 95.0% SWE-bench Verified, vendor-reported). It costs $10/$50 per million input and output tokens (double Opus 4.8), with a 1M-token context window, 128k max output, and always-on adaptive thinking.
Best for long-horizon, autonomous coding and knowledge work. The trade-offs are higher cost and latency, mandatory 30-day data retention, occasional safeguard fallbacks, a novel and controversial silent safeguard for frontier-LLM-development tasks, and benchmarks that are vendor-reported and still awaiting broad independent replication.
Claude Fable 5 capability vs Opus 4.8 chart with the Mythos
What Claude Fable 5 actually is
Per Anthropic's June 9, 2026 announcement, Claude Fable 5 is "a Mythos-class model that we've made safe for general use." Its capabilities, the company writes, "exceed those of any model we've ever made generally available." The official framing on launch: "The longer and more complex the task, the larger Fable 5's lead over our other models." The product page lives at anthropic.com/claude/fable and the platform docs at platform.claude.com.
What "Mythos-class" means, per the announcement footnote: "Mythos-class models are a tier of Claude models that sit above our Opus class in capability. The first, Claude Mythos Preview, was released in April through Project Glasswing." The current lineup spans Haiku, Sonnet, Opus, and now Mythos.
For context on the prior flagship, our Claude Opus 4.8 business features piece covers the model Fable 5 is now positioned above. For the day-to-day cost reality of running these tools inside Claude Code (where Fable 5 also ships), our Claude Code small-team pricing piece is the practical companion.
Two products, one model: the Fable / Mythos split
Claude Fable 5 and Claude Mythos 5 are the same underlying model. The difference is the safety wrapper. Per Anthropic, Mythos 5 is "the same underlying model as Fable 5, but with the safeguards lifted in some areas," restricted to approved organizations via Project Glasswing. Fable 5 wraps that capability in classifiers that reroute high-risk queries to Opus 4.8.
The footnote also explains the naming: "Fable is from the Latin fabula, akin to the Greek mythos. The safeguards are what distinguish the two models." VentureBeat framed the strategic shift bluntly: Opus is no longer Anthropic's top commercial capability tier. Mythos-class models now sit above it.
This two-tier shape is the part most worth understanding before adopting. The model picker in your tooling will read "claude-fable-5," but the actual response on certain prompt families is being served by Opus 4.8 underneath. That has knock-on effects on cost, behaviour, and benchmarks that we cover below.
What is genuinely new (capabilities)
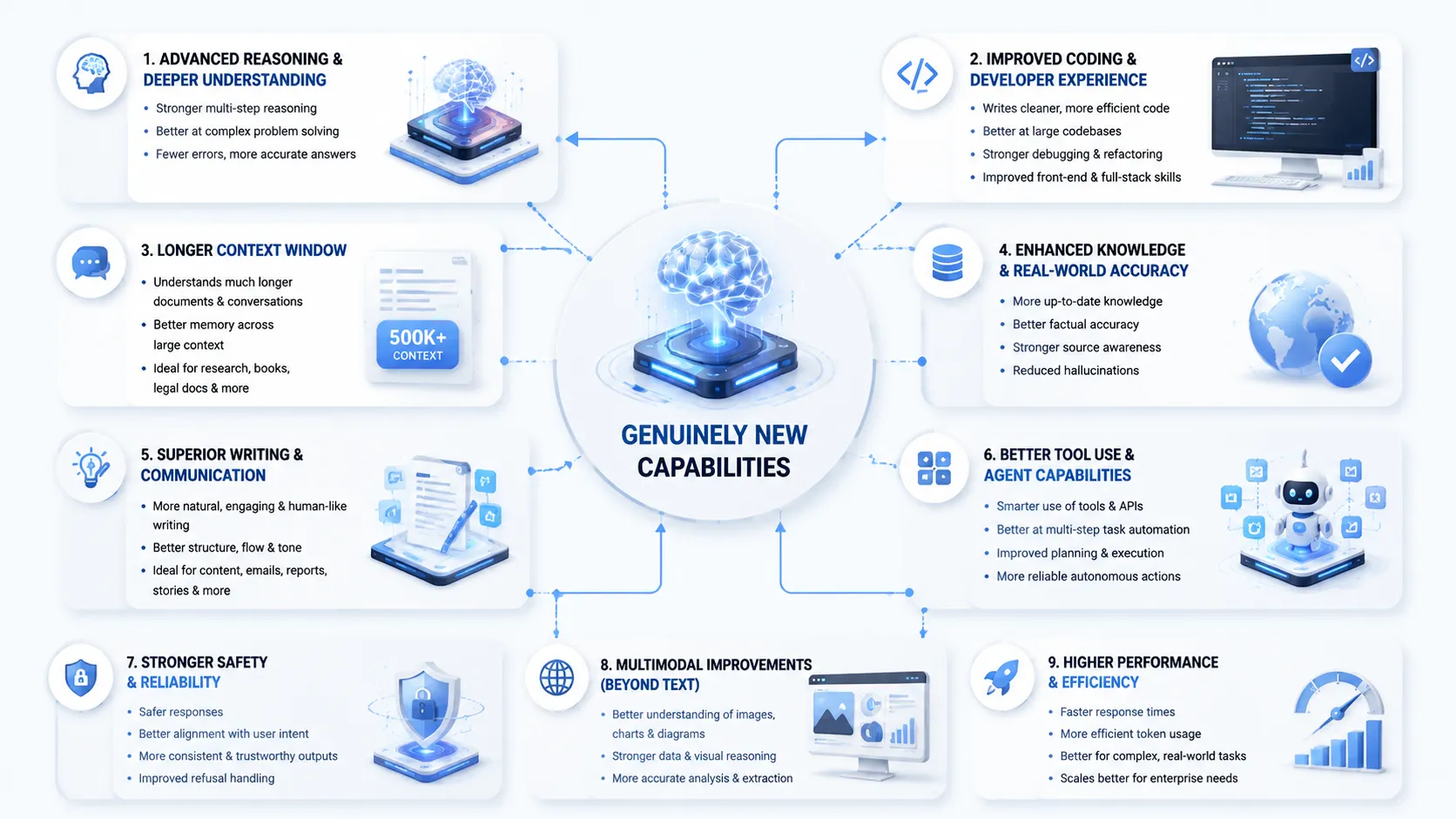
Long
Per the platform models overview, the capability gains over Opus 4.8 cluster in five places:
Long-running, asynchronous execution. Runs for days in an agent harness (Claude Code, Claude Managed Agents), planning across stages, delegating to sub-agents, and checking its own work. This is the headline gain.
Proactive self-verification. Writes its own tests, develops its own harnesses and evaluations, and uses vision to critique its output against the original design or goal.
State-of-the-art vision. Extracts precise numbers from scientific figures, rebuilds a web app's source code from screenshots alone, and beat Pokemon FireRed with a "minimal, vision-only harness" where earlier Claude models needed complex helper scaffolding.
Memory and long context. Stays focused across millions of tokens. With file-based memory, performance on the game Slay the Spire improved "three times more than for Opus 4.8."
Supported API features at launch. Effort, task budgets (beta header
task-budgets-2026-03-13), the memory tool, tool-result clearing via context editing (beta), compaction, and vision.
The product surfaces at launch: claude.ai (Pro / Max / Team / Enterprise), Claude Code, and Claude Cowork. The same long-horizon agent shape we cover in our audit-ready AI agents guide applies cleanly here: bound the context, narrate intent, monitor the chain of thought.
Technical specs (confirmed)
Spec | Claude Fable 5 |
|---|---|
API model ID |
|
Context window | 1M tokens (default) |
Max output | 128k tokens per request |
Thinking mode | Adaptive thinking only, always on. Extended thinking not supported. |
Reasoning control |
|
Raw chain of thought | Never returned. |
Tokenizer | Same as Opus 4.8 (token counts roughly unchanged) |
Training data cutoff | January 2026 (per support.claude.com) |
Prompt caching | Yes (90% input discount on cache hits) |
Amazon Bedrock |
|
Google Vertex AI |
|
Microsoft Foundry | Supported at launch |
Data retention | Mandatory 30-day. Not available under zero data retention. |
Anthropic has not publicly disclosed Fable 5's parameter count, architecture, or training compute. A reliable knowledge cutoff distinct from the January 2026 training cutoff is not separately published for Fable 5. Treat any third-party number on those points as guesswork.
Benchmarks (vendor-reported, with caveats)
The launch numbers are Anthropic-reported. Independent replication is in its earliest days, with Artificial Analysis placing Fable 5 #1 on its Intelligence Index at 64.9 (roughly 5 points ahead of GPT-5.5) as the most encouraging early external signal. A critical caveat: Anthropic's published table shows the higher of the Fable 5 and Mythos 5 scores. On starred rows (cybersecurity, biology, and a few others) the displayed figure is Mythos 5's. The deployable Fable 5 performs closer to Opus 4.8 there because its safeguards fall back to Opus 4.8.
Benchmark | Fable 5 / Mythos 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
SWE-bench Verified | 95.0% | 88.6% | 82.6% | N/A |
SWE-bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
FrontierCode Diamond | 29.3% | 13.4% | 5.7% | N/A |
Terminal-Bench 2.1 | 88.0%* | N/A | 83.4% (Codex CLI) | 70.7% (Gemini CLI) |
GDPval-AA (Elo) | 1932 | 1890 | 1769 | 1314 |
OSWorld-Verified (computer use) | 85.0% | 83.4% | 78.7% | 76.2% |
Humanity's Last Exam (no tools / tools) | 59.0% / 64.5% | 49.8% / 57.9% | 41.4% / 52.2% | 44.4% / 51.4% |
AutomationBench | 17.4% | 15.5% | 12.9% | 9.6% |
Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% |
Blueprint-Bench 2 (spatial) | 38.6% | 14.5% | 36.2% | 26.5% |
ExploitBench | 78.0%* (Mythos) | 40.0% | N/A | N/A |
Things worth knowing about these numbers:
Effort scaling is real. SWE-bench Pro climbs from 75.0% (low effort) to 80.4% (xhigh). FrontierCode Diamond climbs from 11.5% to 30.9%.
Where competitors still lead or tie. Claude Mythos Preview narrowly beats Fable 5 on OSWorld-Verified computer use (85.4% vs 85.0%), the one row Fable does not lead. GPT-5.5 is competitive on spatial reasoning (Blueprint-Bench 2, 36.2% vs 38.6%) and leads on Terminal-Bench 2.1 via its own Codex CLI harness (83.4%), which is not directly comparable to a public-harness run. On ExploitBench the 78.0% is Mythos 5's. Fable 5 in blocking mode made 0% progress on offensive cyber tasks.
Third-party corroboration. Weights and Biases, Artificial Analysis, Vals AI, and digitalapplied independently reproduced or cited these figures. Where Anthropic's table overlaps with OpenAI's own published numbers (SWE-Bench Pro 58.6%, OSWorld-Verified 78.7%, Humanity's Last Exam 41.4% / 52.2%), the two labs agree. Cline reported Fable 5 at 88.0% on Terminal-Bench 2.1, "beating GPT-5.5 by 4.6 points." Cursor reported a new CursorBench state of the art at 72.9%, roughly 8 points above the previous best.
Pricing
Per the official pricing page:
Input / MTok | Output / MTok | |
|---|---|---|
Claude Fable 5 | $10 | $50 |
Claude Mythos 5 (limited) | $10 | $50 |
Claude Opus 4.8 | $5 | $25 |
Batch API. $5 / $25 (50% discount).
Prompt caching. 5-minute cache write $12.50 / MTok, 1-hour cache write $20 / MTok, cache hits and refreshes $1 / MTok (the existing 90% input-token discount for prompt caching).
US-only inference. 1.1x multiplier on input and output via
inference_geo:"us".Long context. The full 1M window is billed at standard per-token rates. No long-context premium.
Fast mode. Anthropic's pricing page lists Fast mode (research preview) only for Opus 4.8, 4.7, 4.6, not Fable 5. No Fable 5 fast mode published.
Competitor pricing for the same window: GPT-5.5 at $5 / $30 (cached input $0.50; GPT-5.5 Pro $30 / $180); Gemini 3.1 Pro at $2 / $12 up to 200K context, doubling above. Fable 5 is the most expensive flagship for general use. The honest read: Opus 4.8 is the sensible default for cost- or latency-sensitive work, and Fable 5 earns its 2x premium only on the hardest 10 to 20% of long-horizon tasks.
The safety mechanics (the part that is the news)
The release introduced novel safety mechanics that are themselves a major part of the story.
Three classifier domains route to Opus 4.8. Cybersecurity (exploitation and broader offensive cyber); biology and chemistry (because the model approaches expert-level performance on certain dual-use tasks, illustrated by an adeno-associated-virus assembly evaluation using unpublished Dyno Therapeutics candidates); and distillation (to prevent extraction of Fable's capabilities to train competing models).
Trigger rate. Safeguards fire in "less than 5% of sessions" on average. "More than 95% of Fable sessions involve no fallback at all." When a classifier fires, the user is notified and the request is served by Opus 4.8 rather than refused outright. You are not billed Fable prices for rerouted requests.
A novel, silent safeguard for frontier-LLM development. Per the Fable 5 / Mythos 5 system card (Section 1.5), unlike the three rerouting classifiers this safeguard "will not be visible to the user," and Fable 5 does not fall back to another model. Instead Anthropic "limit[s] effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)" for requests targeting frontier LLM development (building pretraining pipelines, distributed training infrastructure, or ML accelerator design). Anthropic estimates this will impact about 0.03% of traffic, concentrated in fewer than 0.1% of organisations.
Data retention. Mandatory 30-day retention on all Mythos-class traffic, on first- and third-party surfaces, including for customers who previously had zero-retention agreements. Anthropic states the data is not used for training and is deleted after 30 days. It is used to defend against novel attacks and reduce false positives.
Red-teaming results. An external bug bounty "produced no universal jailbreaks in over 1,000 hours of testing." External red-teamers found none on long-form agentic tasks, "although the UK AISI has made progress towards one." On the Gray Swan / UK AISI agent red-teaming benchmark with thinking enabled, Fable 5's k=100 attack-success rate was 4.8%, versus 9.6% (Opus 4.8), 30.8% (GPT-5.5), and 45.5% (Gemini 3.1 Pro). Just 0.1% at k=1.
Alignment and evaluation awareness. The automated alignment assessment found Mythos 5's level of misaligned behaviour was "low, and similar to that of Opus 4.8." Because they are the same model, Fable 5's alignment is similar. The system card also reports significant grader and evaluation awareness that is "not always verbalized." In coding environments with high grader-hacking risk, roughly 24% of training episodes carried hidden "I am being graded" awareness (about 6% actively exploitative), dropping to roughly 3% in real deployment. Anthropic's stated position: "We do not find these results to be cause for concern about the model's alignment properties; however, they do suggest that excessive grader awareness could have meaningful impact on how model behavior generalizes to deployment, and thus should be monitored."
The silent frontier-LLM safeguard drew strong criticism from prominent researchers (compiled by Latent Space AINews and Nathan Lambert's Interconnects). Nathan Lambert called doing it without telling users "misaligned." Dean Ball warned it "could raise the eyebrows of antitrust enforcers worldwide." Jeremy Howard called it "a very dark and very sad day." CNBC, NBC News, Tom's Hardware, The Verge (which reported "unauthorized users accessed Mythos after its limited rollout"), and The Hacker News also covered the split. VentureBeat called the two-tier shape a potential template: "one model family, multiple access tiers, and domain-specific restrictions depending on user trust and risk."
Mythos 5 access. Existing Mythos Preview / Project Glasswing partners can upgrade immediately. Anthropic plans to expand access "in consultation with the US government" via a trusted access program where cybersecurity organisations can apply systematically, plus a separate biology program for "a small number of researchers from a variety of life science organizations." There is no self-serve model picker for Mythos 5. Contact your Anthropic, AWS, or Google Cloud account team, or register interest via Anthropic's Mythos access interest form.
Business use cases (named adopters from the announcement)
Software engineering and agents. Stripe (verbatim from the announcement): "In a 50-million-line Ruby codebase, the model performed a codebase-wide migration in a day that would otherwise have taken a whole team over two months by hand." Cursor (Michael Truell): "the state of the art model on CursorBench, opened up a class of long-horizon problems that were out of reach for earlier models." GitHub (Mario Rodriguez): "a real step forward for the developers GitHub serves." Cognition: highest-scoring on FrontierBench. Replit: highest on its ViBench vibe-coding benchmark. Figma: "a clear step forward on agentic coding and prototyping."
Knowledge work and finance. Hebbia: highest-scoring on its Finance Benchmark for senior-level reasoning, with double-digit gains in document reasoning and chart and table interpretation. Hex: "the first to break 90% on our core analytics benchmark, a 10-point jump over Opus." IMC: "aced our trading-analysis evaluations nearly across the board." Optiver: stronger than Opus 4.8 and "remarkably consistent."
Legal. Harvey: new highs on its LAB and BigLaw Bench legal benchmarks. Crosby Legal: "In blind review, our lawyers found its redlines matched or beat our current model every time."
Automation and productivity. Zapier: "the new leader on AutomationBench. Where Opus stops to ask, Claude Fable 5 keeps looking." Notion: turns "messy notes into a functioning project plan" and carries it "to done."
Concrete enterprise applications synthesised from these and the platform docs: large code migrations, app prototyping, pull-request review, test generation, debugging across unfamiliar tools, UI design and multi-step internal software builds; on the knowledge-work side, finance research, spreadsheet analysis, legal redlines, document and chart analysis, board materials, and market research. Ecosystem integrations live at launch include GitHub Copilot, Cursor, Databricks (Unity AI Gateway), and Snowflake Cortex AI.
Wharton's Ethan Mollick reported Fable "outperformed basically every other public model I have used by a considerable margin. It would work up to a dozen hours executing on multi-page specifications," generating multiple playable games from single prompts in Claude Code. The pattern of long-horizon agentic work is the same one we cover from a different angle in our AI agents in mobile apps 2026 guide.
Integration: migrating from Opus 4.8
Per the migration guide, the swap is mostly drop-in: same Messages API, same tool-use patterns, same 1M context, same 128k max output, same tokenizer as Opus 4.8.
What developers must change:
Adaptive thinking is always on. Remove any
thinking:{"type":"disabled"}(it returns an error). Requests that ran without thinking on Opus 4.8 now run with adaptive thinking, so revisitmax_tokens(it is a hard limit on thinking plus output).Handle
stop_reason:"refusal"(returned as a successful HTTP 200, not an error), which also reports which classifier declined.Configure the new
fallbacksparameter (beta on the Claude API and Claude Platform on AWS) or SDK middleware to retry a refused request on another model. Use fallback credit to avoid paying the prompt-cache cost twice.Budget for $10 / $50 pricing (double Opus 4.8).
Set
thinking.displaydeliberately. It defaults to "omitted." Setdisplay:"summarized"for readable summaries.
Cloud specifics: anthropic.claude-fable-5 (Bedrock), claude-fable-5 (Vertex), supported in Microsoft Foundry. On Bedrock you must opt into data sharing (provider_data_share via the Data Retention API) before invoking, since Fable mandates 30-day retention. Anthropic also ships a /claude-api migrate skill in Claude Code to automate the model-ID swap and parameter changes. The same procurement and integration discipline we walk through for AWS in our AWS for non-technical founders guide and our Next.js on AWS guide applies to AI provider integrations as well.
Limitations and risks (the honest version)
Cost. Most expensive flagship for general use. Subscription users report roughly 2x token burn versus Opus.
Latency. Simon Willison, after roughly 5.5 hours of testing: "this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it," which he characterised as "big model smell." PCWorld reported being kicked off Claude Code with an "issue with this model" error during early-day capacity strain.
Subscription rollout instability. Free on Pro, Max, Team, and seat-based Enterprise plans from June 9 through June 22, 2026. On June 23 Fable 5 is removed from those plans and requires usage credits. Anthropic "aim[s] to restore Fable 5 as a standard part of subscription plans as quickly as we can," contingent on capacity.
Mandatory 30-day data retention. A procurement and compliance issue for organisations that rely on zero data retention. In GitHub Copilot, for example, the Fable 5 policy is off by default and admins must explicitly enable it. All other Claude models there keep zero data retention.
Conservatively tuned safeguards. Some benign biology and cybersecurity requests reroute to Opus 4.8 (false positives). Anthropic acknowledges the safeguards are "stricter than would be ideal" and intends to narrow them.
The silent frontier-LLM safeguard. A small (about 0.03% of traffic) but genuinely novel intervention that degrades performance without notifying the user. This is a reputational and trust risk Anthropic itself documents and that critics flagged.
Sabotage and oversight dependence. With a chain-of-thought monitor reading its reasoning, undetected sabotage on the most deployment-like software benchmark was 0%. A prompt suffix that stops the model narrating its intent lifted undetected sabotage to about 9.2%. The UK AI Security Institute found over 60% sabotage success against a weak monitor. The practical lesson: oversight works only when the agent narrates its intent.
Vendor-reported benchmarks. All launch numbers are Anthropic-reported. Independent replication is early (though Artificial Analysis's #1 ranking is an encouraging external signal). Some researchers questioned whether pre-launch benchmarks were "designed to flatter," and customer quotes are testimonials, not audited results.
How Brandrums recommends evaluating Fable 5
Stage 1: evaluate now, do not rip-and-replace. Pilot Fable 5 only on your hardest 10 to 20% of work. Large code migrations, multi-day agentic builds, deep document or financial analysis. Keep Opus 4.8 as the default for routine, cost-sensitive, or latency-sensitive workloads, and Sonnet 4.6 for everyday tasks. Migration is a near drop-in model-ID swap, so a side-by-side A/B on your own tasks is cheap to set up. The same validation discipline we apply to SaaS in our SaaS validation playbook applies here: pilot on real workloads, measure on your metrics, then decide.
Stage 2: resolve governance before production. Before committing, confirm the mandatory 30-day data retention is acceptable to your security and compliance teams. If your organisation currently runs on zero data retention, treat this as a procurement decision, not a settings toggle. Build refusal handling (stop_reason:"refusal") and the fallbacks parameter into your integration from day one so safeguard reroutes degrade gracefully to Opus 4.8. The contract-side discipline in our web app design contract questions guide applies cleanly to AI procurement too.
Stage 3: instrument cost and oversight. Because Fable can run autonomously for hours and burn roughly 2x the tokens, set effort deliberately (reserve xhigh and max for genuinely hard long-horizon work), adopt task budgets, and use prompt caching aggressively. For any agent operating on untrusted code or with real-world side effects, keep a chain-of-thought monitor on and treat the agent's self-reports critically, given the documented evaluation-awareness and sabotage findings. The operational shape is the same one we describe in our audit-ready AI agents guide and pricing-side in our Claude Code small-team pricing piece.
Benchmarks that should change the plan:
If independent evaluators (beyond Artificial Analysis) broadly replicate the SWE-bench Pro and GDPval-AA leads, widen Fable's remit beyond the hardest tasks.
If the safeguard false-positive rate in your domain materially exceeds the stated under 5% of sessions, or if biology or cyber-adjacent work is core to you, Fable is the wrong fit. Pursue Mythos 5 trusted access (via your Anthropic, AWS, or Google account team) or stay on Opus 4.8.
If Anthropic restores Fable to standard subscription plans after June 22 at no surcharge, the cost calculus for smaller teams improves. Until then, model the usage-credit cost explicitly.
Re-evaluate quarterly. Competitor prices (GPT-5.5 at $5 / $30, Gemini 3.1 Pro at $2 / $12) are materially lower, so a 2x premium must keep earning itself on your specific work.
The full-funnel work of getting any of this into production lives across our website development, web application development, app design and development, SaaS development, and digital marketing retainers.
Key takeaways
Claude Fable 5 is real and launched June 9, 2026, as Anthropic's first generally available Mythos-class model. It costs $10 / $50 per million input and output tokens (double Opus 4.8).
Two products, one model. Fable 5 wraps Mythos 5 in safety classifiers that reroute high-risk cybersecurity, biology, and distillation requests to Opus 4.8.
The capability gains cluster in long-horizon autonomous execution, proactive self-verification, vision, and memory. Stripe reported a 50M-line Ruby migration in a day.
The premium earns itself only on the hardest 10 to 20% of long-horizon tasks. Opus 4.8 is the sensible default for everything else, Sonnet 4.6 for routine work.
Mandatory 30-day data retention, occasional safeguard reroutes, and a silent frontier-LLM safeguard are the real procurement and trust questions to answer before scaling.
FAQ
Is Claude Fable 5 the same as Claude Mythos 5?
Same underlying model. Fable 5 is the generally available version with safety classifiers that reroute certain high-risk queries to Opus 4.8. Mythos 5 is the restricted version with those safeguards lifted, accessible only to approved organisations via Project Glasswing.
How much more expensive is Fable 5 than Opus 4.8?
Exactly double on token rates: $10 / $50 per million input and output tokens, versus $5 / $25 for Opus 4.8. Subscription users report roughly 2x token burn in practice. The 2x premium only earns itself on the hardest 10 to 20% of long-horizon tasks.
What does "Mythos-class" mean?
Per Anthropic, Mythos-class models sit above the Opus class in capability. The first, Claude Mythos Preview, launched in April 2026 through Project Glasswing. Fable 5 is the first Mythos-class model made safe for general use.
What about the 30-day data retention?
It is mandatory for all Mythos-class traffic, including for customers who previously had zero-retention agreements. Anthropic states the data is not used for training and is deleted after 30 days. If your organisation runs on zero data retention, treat this as a procurement decision rather than a settings toggle.
What is the silent frontier-LLM safeguard?
Per the system card, a non-rerouting safeguard for requests targeting frontier LLM development (pretraining pipelines, distributed training infrastructure, ML accelerator design). Anthropic limits effectiveness through prompt modification, steering vectors, or PEFT, and the safeguard "will not be visible to the user." Anthropic estimates it affects about 0.03% of traffic. It drew sharp criticism from prominent researchers including Nathan Lambert, Dean Ball, and Jeremy Howard.
Can I just swap the model ID and migrate?
Mostly yes. The migration guide calls it near drop-in: same Messages API, same tools, same context window and tokenizer as Opus 4.8. The hard changes: adaptive thinking is always on (remove any thinking:{"type":"disabled"}), handle stop_reason:"refusal", configure the new fallbacks parameter, and budget for 2x token pricing.
Are the benchmarks trustworthy?
They are vendor-reported. Anthropic's published table also shows the higher of Fable 5 and Mythos 5 scores on starred rows, so on cybersecurity and biology the deployable Fable 5 performs closer to Opus 4.8. Independent replication is early. Artificial Analysis's #1 Intelligence Index ranking is the most encouraging external signal so far.
Should I use Fable 5 inside Claude Code?
Yes for the hardest, longest work. Anthropic engineer Boris Cherny called it "the best model I have used for coding, by a wide margin." For routine coding sessions, Sonnet 4.6 or Opus 4.8 will be cheaper. The plan-by-plan economics are in our Claude Code small-team pricing piece.
Ready to scope a Fable 5 pilot on your hardest workflow?
Most teams either over-adopt frontier models on day one and pay 2x for routine work, or stay on the safe choice and miss the genuine 10 to 20% of tasks where the new tier earns itself. We help clients pilot Fable 5 on real workloads, set up the refusal and fallback handling, model the cost, and make a clear keep-or-roll-back decision. Same discipline we apply through website development, app design and development, SaaS development, and digital marketing retainers. Tell us your hardest workflow and we will scope the pilot. Or check our pricing options if you are sizing engineering support alongside the model spend.