
Key takeaways
An audit-ready AI agent is one whose every decision can be replayed, explained, and defended in front of a regulator, a customer, or a courtroom.
The four building blocks are structured outputs, a decision trace per run, a versioned eval suite, and deterministic replay from stored inputs.
EU AI Act Article 12 requires automatic event logging for high-risk systems with a six-month retention floor, and Annex III duties go live on August 2, 2026.
Treat traces and evals as product surfaces, not afterthoughts. They decide whether the agent ships, gets paused, or gets rolled back.
Most failures in regulated AI come from missing context in the log, not from the model being wrong.
Why audit-ready is the new bar for AI agents
For two years the conversation about AI agents was about capability. Can the agent book the trip, file the claim, close the ticket? In 2026 the question has shifted. Capability is assumed. Buyers in finance, health, energy, and legal now ask the harder one: if the agent makes a decision, can you tell me, under oath, exactly what it did and why?
That is what audit-ready means. Not a chat screenshot. A reproducible record of inputs, prompts, model version, tool calls, retrieved documents, policy checks, confidence values, and final output, stored so a third party can replay the run and reach the same outcome. If your agent cannot do this, it does not belong in a regulated workflow. We build these systems through AI solutions for regulated industries, and the pattern below is what survives real audits.

Diagram of an audit
The cost of getting this wrong is no longer theoretical. EU AI Act Annex III obligations take effect on August 2, 2026, with a six-month minimum log retention for high-risk systems and penalties up to 15 million euros or 3 percent of worldwide turnover. In the US, the NIST AI Risk Management Framework names traceability and accountability as core functions. The AI observability market hit $1.1 billion in 2025 on its way to a projected $3.4 billion by 2035, which tells you where mature buyers are putting budget.
What an audit-ready decision trace contains
A decision trace is a single structured record per agent run. It is not a log file. It is a contract with your future self, your regulator, and your incident-response team. The minimum fields we ship for clients in AI for fintech and healthcare workflows look like this.
Field group | What it captures | Why an auditor cares |
|---|---|---|
Identity | Run ID, user ID, tenant ID, parent trace ID | Links the decision to a real person and session |
Input | Raw user message, attached files (hashed), system prompt version | Proves what the agent saw |
Model | Provider, model ID, version, temperature, seed | Reproduces the call with the same weights |
Retrieval | Query, document IDs, chunk hashes, vector store version | Shows which evidence grounded the answer |
Tools | Tool name, arguments, result, latency, retry count | Confirms which external systems were touched |
Policy | Rule IDs that fired, allow or deny verdicts, redactions | Demonstrates guardrails ran, not just that they exist |
Output | Final structured response, confidence scores, review flag | The decision in a form a non-engineer can read |
Cost | Input tokens, output tokens, dollar amount, wall time | Ties governance to unit economics |
Two design rules matter more than the schema. First, write the trace before the response leaves the system. A trace written after delivery can be skipped during a crash or quietly edited later. Second, store traces append-only with cryptographic hashes that chain runs together. WORM storage, an immutable Postgres table with row hashing, or an object store with object lock all work. The property you want is simple: if someone tampers with a past trace, the next audit detects it.
Structured outputs are the foundation
You cannot audit free-form prose at scale. A regulator wants to know that on March 14 the agent denied loan application 4429 because debt-to-income breached policy R-12, not that the agent wrote three paragraphs about it. That requires the model to return a typed object every time, with the reason code as an enum and the policy ID as a string.
Every major provider supports schema-constrained generation: JSON Schema with OpenAI, strict tool use with Anthropic, grammar-constrained decoding on open-weight stacks. Use them. If you are picking a model for this work, our Claude Opus 4.8 deep dive covers how the newer reasoning models handle long tool chains and structured outputs in production. Three habits matter:
Version the schema with the prompt. A change to either is a new model card.
Reject and retry on schema violation rather than parsing best-effort.
Store the schema version inside the trace so a replay six months later picks the right validator.
Structured outputs also unblock downstream automation. If your agent feeds a billing system, a CRM, or a claims engine, you want a typed contract, not a regex on the model's reply. Same discipline we apply when scoping enterprise app development projects where AI sits behind a workflow that touches money or patient data.
The eval suite is your unit test layer for behavior
Traces tell you what happened. Evals tell you whether what happened was correct, before you ship. A serious eval suite for a regulated agent has four layers.
Golden cases
A few hundred frozen examples written by domain experts, with expected outputs and tool-call sequences. Runs on every deployment. Anything red blocks the release.
Adversarial cases
Jailbreaks, contradictory instructions, missing fields, hostile inputs, and edge cases pulled from past incidents. The first time a real incident happens, it becomes a permanent entry here.
LLM-as-judge for the long tail
A stronger model scores the agent's free-form output against a versioned rubric. Useful for thousands of cases where hand-grading does not scale. Pin the judge model, or your score moves under you.
Production sampling
A small percentage of live runs gets graded continuously. This is the canary that catches drift, vendor model updates, and data shifts the static suite misses. Arize, LangSmith, Braintrust, and Confident AI all support this pattern out of the box.

Four
The common mistake is treating evals as a research artifact instead of a release gate. Wire them into CI like unit tests. When we build agents end to end, this sits beside the regular web application development pipeline and runs on every pull request that touches a prompt, a tool, or a model version.
Replay is what turns a log into evidence
A trace that cannot be replayed is a story. Deterministic replay means you can take a stored trace, point it at the same model version with the same seed, the same retrieved documents, and the same tool stubs, and watch the agent produce the same output. Sounds obvious until you try it.
Three things break replay in practice. Vendor model versions change silently, so pin the version string in every call and refuse to fall back. Tool results from external APIs drift, so record the raw response in the trace and replay against the recording, not the live API. Retrieval indexes get rebuilt, so store the chunk hashes of every retrieved document and serve them from a frozen snapshot during replay.
With all three in place, replay becomes the most useful tool you own. You can reproduce a customer complaint from six months ago, test a prompt change against a year of real traffic before shipping, or hand a regulator a USB stick and let them rerun the decision. The AI and machine learning in modern app development guide covers how this fits the broader product lifecycle.
Traceability requirements by regulated industry
The principles are the same across sectors, but the specifics differ. Here is what we ship by default for each, drawing on what we have learned across industries we work with.
Industry | Frameworks that apply | Trace fields you cannot skip |
|---|---|---|
Banking and credit | EU AI Act, ECOA, GDPR, SR 11-7 | Reason codes, adverse action explanation, feature attributions, reviewer ID |
Clinical decision support | FDA SaMD, HIPAA, EU AI Act, MDR | Patient ID hash, source guideline ID, confidence band, clinician override |
Insurance claims | NAIC Model Bulletin, state DOI rules, GDPR | Policy ID, factors used, exclusions checked, fraud rationale |
Legal and contracts | Bar guidance, client confidentiality, EU AI Act | Matter ID, document version, citation list, confidence per clause |
Energy and grid | NERC CIP, ISO safety standards | Sensor snapshot, control action, safety envelope check, operator confirmation |
EU AI Act Article 12 requires automatic event recording across the lifetime of a high-risk system, and Article 26 puts the retention duty on deployers for at least six months. According to Help Net Security's April 2026 analysis, the regulation does not prescribe a schema, but providers must document how deployers can collect and interpret the logs. That is design freedom plus a duty to write a clear log spec for your customers.
The reference architecture we deploy
The shape of a defensible system has settled into a small number of moving parts:
Agent runtime: orchestrates model, tools, retrieval, and policy. LangGraph, CrewAI, or a thin in-house orchestrator.
Policy layer: a deterministic rules engine that runs before and after the model. OPA, Cerbos, or a typed rules module. This is where you encode "never write to the production ledger without two-factor approval."
Trace pipeline: OpenTelemetry spans for engineers, plus a domain trace the orchestrator writes for compliance.
Eval and replay store: a versioned dataset of past runs, schema-validated, rerunnable against any prompt and model version.
Immutable archive: WORM object storage with a retention lock. Six months is the EU floor; financial services usually hold for seven years.
Review console: a UI that lets a non-engineer open a run, see the decision and evidence, and approve, reject, or escalate.
When the surrounding product matters, the team that ships the agent usually owns the customer-facing mobile app and the SaaS backend that calls it. One roof is the difference between a trace that is technically correct and one that ties cleanly to a real business event.
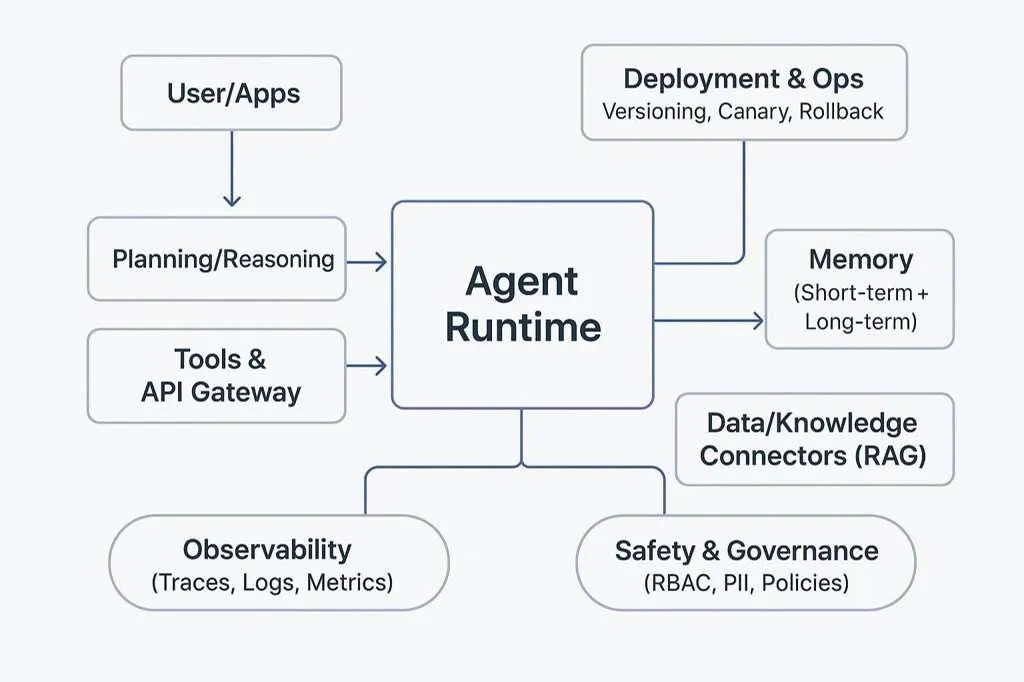
Reference architecture diagram showing agent runtime, policy layer, trace pipeline, eval store, immutable archive, and review console, before architecture section
A 60-day plan to retrofit an existing agent
Most teams reading this already have an agent in production. You do not need to rebuild. Add four layers in this order.
Days 1 to 14: structured outputs and a typed trace
Move every model call to schema-constrained generation. Define one trace schema and write it from the orchestrator before the response is returned. Stop writing plain-text logs. Start writing typed records to a store with append-only semantics.
Days 15 to 30: the first eval suite
Pull 200 real past runs. Have a domain expert label the correct output for each. Wire them into CI. Block deploys on regression. This alone catches most bad prompt changes before they reach users.
Days 31 to 45: replay and policy
Pin model versions. Record tool responses in the trace. Freeze a retrieval snapshot per release. Add a deterministic policy layer for rules you currently enforce by prompt. Prompts persuade. Policies prove.
Days 46 to 60: the review console
Ship a minimal UI that lets a compliance reviewer open a run and see the full trace as a human-readable story. This is the artifact you show in a sales call to a regulated buyer, and it often closes the deal faster than a slide on accuracy.
A focused team can do this in two months. We often run it as a sprint inside a broader AI MVP development engagement when an agent is heading into a regulated workflow for the first time.
What this looks like in real products
A claims-triage agent for an insurer writes a trace for every claim it routes, including the three policy clauses it considered and the confidence on each. When a customer disputes a denial, the adjuster opens the trace, confirms or overrides, and the override feeds next week's eval suite.
A KYC agent for a fintech runs three deterministic policy checks before and after the model. The model can argue for an exception; the policy layer has the final word. Every exception lands in the trace, gets sampled weekly, and is reviewed by compliance. This is the pattern we recommend for any B2B software workflow where the AI sits next to money movement or identity decisions.
Key takeaways
Audit-ready means reproducible. A run a regulator can replay six months later is the bar.
Structured outputs, a typed decision trace, an eval suite, and deterministic replay are the four mandatory layers.
EU AI Act Article 12 demands automatic event logging with at least six months of retention. Annex III obligations are live from August 2, 2026.
Wire your evals into CI as release gates, not as research dashboards.
The review console is the artifact that turns a trace from engineering output into business and legal evidence.
FAQ
What is the difference between an AI agent log and a decision trace?
A log is unstructured text for engineers. A decision trace is a typed, schema-validated record of a single agent run, with identity, inputs, model version, retrieval, tool calls, policy verdicts, and final output, written before the response leaves the system. A trace is what a regulator can read and replay. A log is what you grep when something breaks.
Do small AI agent deployments need this rigor?
If the agent influences a financial, medical, legal, safety, or hiring decision, yes, regardless of scale. For internal meeting summaries, structured outputs and a basic trace are enough. The test: if this decision were challenged, can you explain it. If not, you need the full stack before going live.
How does the EU AI Act affect US-only deployments?
If the system is offered to users in the EU or its output is used there, the Act applies even if the company is US-based. Many US firms adopt the same logging and retention standard globally to avoid running two stacks. NIST reaches similar conclusions on traceability, so the work is rarely wasted.
How long should we keep AI agent decision traces?
The EU AI Act floor is six months for high-risk systems. Financial services firms usually hold for seven years to align with SEC and banking rules. Healthcare often holds for the life of the patient record. Pick the longest applicable retention and design storage costs around it from day one.
Can we use open-source models and still be audit-ready?
Yes, and in some ways it is easier. You can pin weights, run on your own infrastructure, and avoid silent vendor updates. The trade-off is you own the evals, the safety stack, and ongoing model maintenance. For most regulated buyers we recommend a hybrid: a frontier model for the hard reasoning, a smaller pinned model for the deterministic checks.
Ready to make your AI agent defensible?
If you are deploying an AI agent into a regulated workflow, or your current agent cannot produce a clean trace on demand, we can help close the gap. Brandrums builds and retrofits audit-ready AI systems, with structured outputs, decision traces, eval suites, and replay wired into the build from day one. Talk to our AI team about your agent, or review our engagement pricing to see how a 60-day audit-readiness sprint fits your budget.


